Для быстрого запуска нам понадобиться виртуальный(или физический) сервер от 8gb ОЗУ+2Core + 80Gb sdd/hdd с ubuntu 14.0.4 на борту.
В статье используется сервер с ценой 2,24 рубля/час
для быстрой установки воспользуемся скриптом
Пока устанавливаются все компоненты ознакомимся с содержимым скрипта установки. Скрипт подключает репозиторий docker устанавливает docker-engine + docker-compose и запускает официальные образы elasticsearch и kibana. В docker-compose.yml прописаны первоначальные настройки для корректной работы комплекса на 8Gb ОЗУ. Также мы создаем файл подкачки
Проверить работу системы можно по адресу
http://YOUR_IP:5601/ например http://89.223.26.211:5601/
Если все хорошо - Вы увидите интерфейс kibana.
!!!Внимание!!! - это учебная статья и по ее результатам у нас будет открытый доступ к портам 9200 и 5601
Таблица нагрузок на виртуалках simplecloud
- 4Gb 1core - 1000rps
- 8Gb 2core - 2000rps
- 16Gb 4core - 3000rps - (подозрения что не умеем тюнить elasticsearch)
Настройка fluentd для доставки логов в elasticsearch
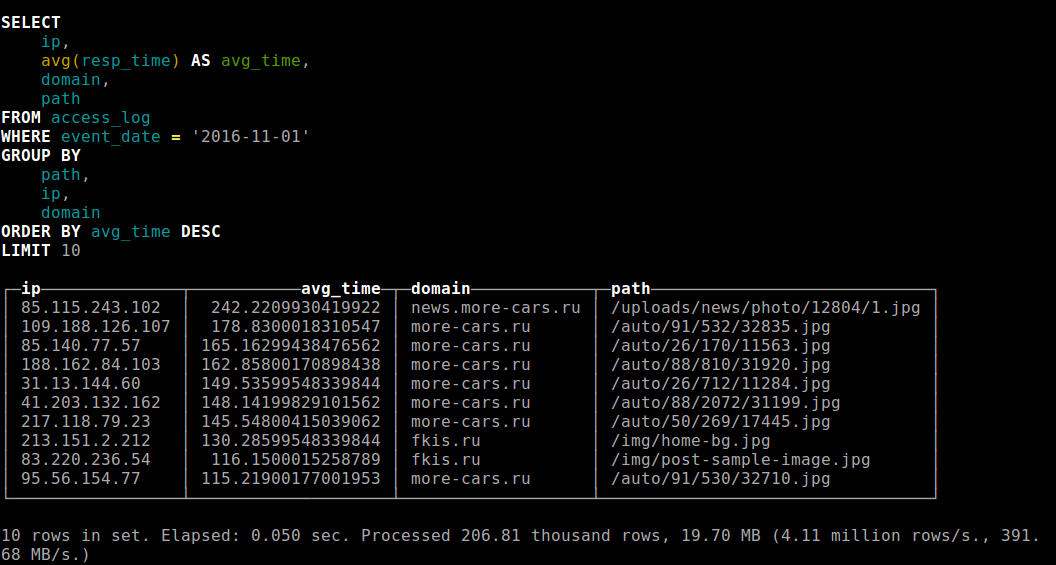
В nginx я использую кастомный лог с добавление данных о схеме и домене запроса и времени ответа
http://yourtver.ru 40.77.167.84 - - [27/Dec/2016:02:37:05 +0300] "GET /firma81601/ HTTP/1.1" 200 4341 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)" "-" "-" 0.092
Разберем конфиг td-agent.conf
Секции source отвечает за обработку источника данных. В нашем примере это плагин tail следящий за изменениями log файла
format отвечает за атрибуты доступные в логе после доставки данных о записи в центральное хранилище
types - отвечает за тип данных после разбора( по умолчанию все данные имеют тип string)
Секция filter Позволяет проводит дополнительную обработку данных в примере ниже мы добавляем данные о hostname и скорости отдачи. В дальнейшем это позволит нам проводить фильтрацию по этим данным
Секция match Отвечает за сохранение данных. В нашем случае мы используем plugin elasticsearch
В блоке мы определяем тип плагина используемого для сохранения данных. Значения буферов используемых для накопления поступающих событий и оптимизации их сброса в elastcisearch
Полный вариант td-agent.conf
Установим td-agent из deb пакетов используя скрипт установки с официально сайта и воспользуемся демо конфигом подготовленным для данной статьи
curl -L https://toolbelt.treasuredata.com/sh/install-ubuntu-trusty-td-agent2.sh | sh curl -L https://goo.gl/SMW2GO > /etc/td-agent/td-agent.conf
td-agent-gem install fluent-plugin-elasticsearch /etc/init.d/td-agent restart
Сбор данных и работа с kibana
Для первого знакомства и получения опыта нам потребуется тестовый набор данных. Для быстрого наполнения воспользуемся log файлом с моего тестового сервера
git clone https://github.com/asigatchov/demo_efk.git cd demo_efk
Тк td-agent написан на ruby, воспользуемся установленным интерпретатором для генерации лога и наполнения данных
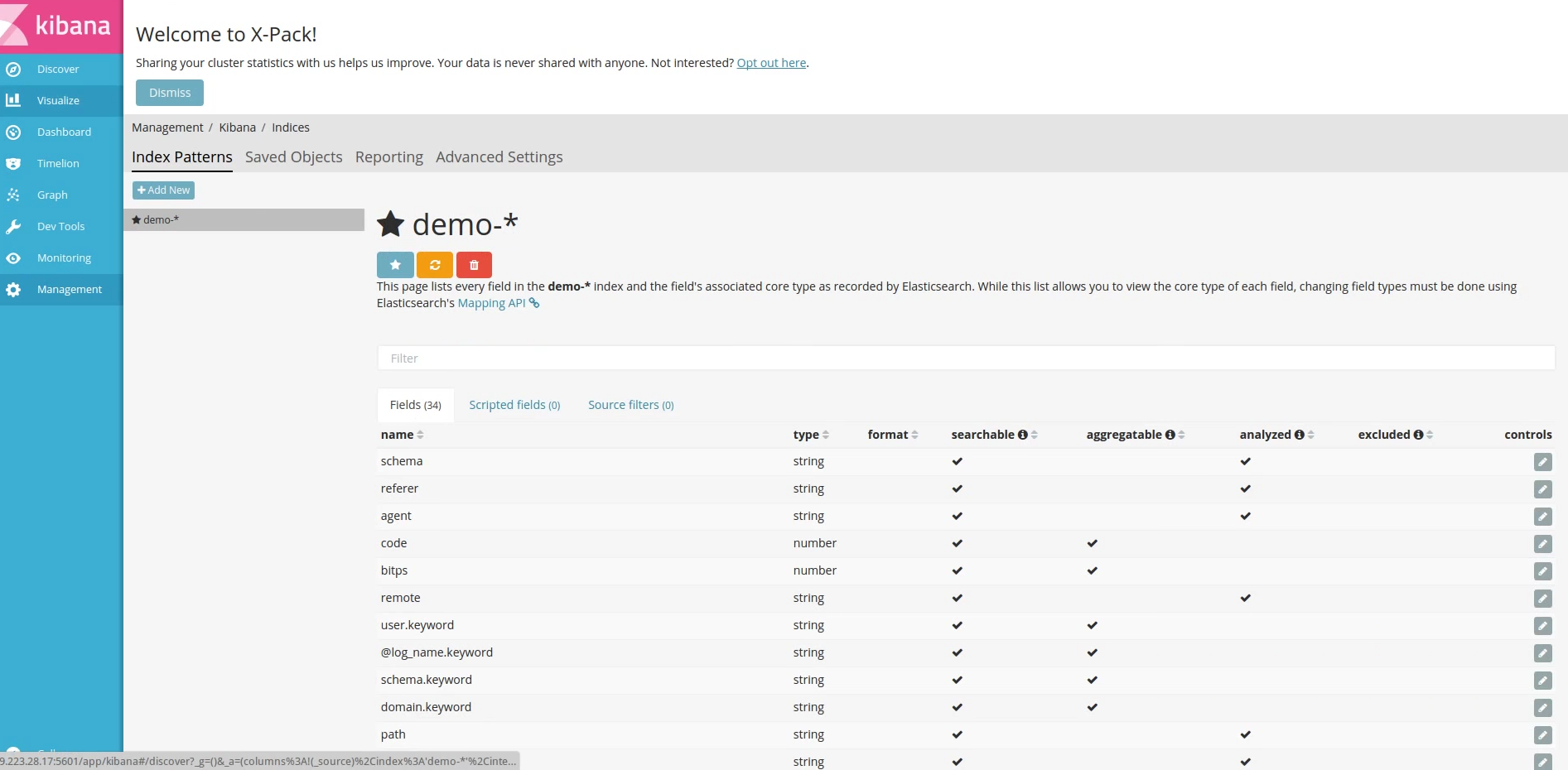
После окончания работы лога генератора у нас есть данные за последние сутки. Теперь перейдем в kibana и настроим индекс для работы. В screencaste мы указываем имя индекса demo. Под таким именем указали fluentd сохранять наши данные в блоке match